

A PowerBook G4 running a TinyStories 110M Llama2 LLM inference — Image credit: Andrew Rossignol/TheResistorNetwork
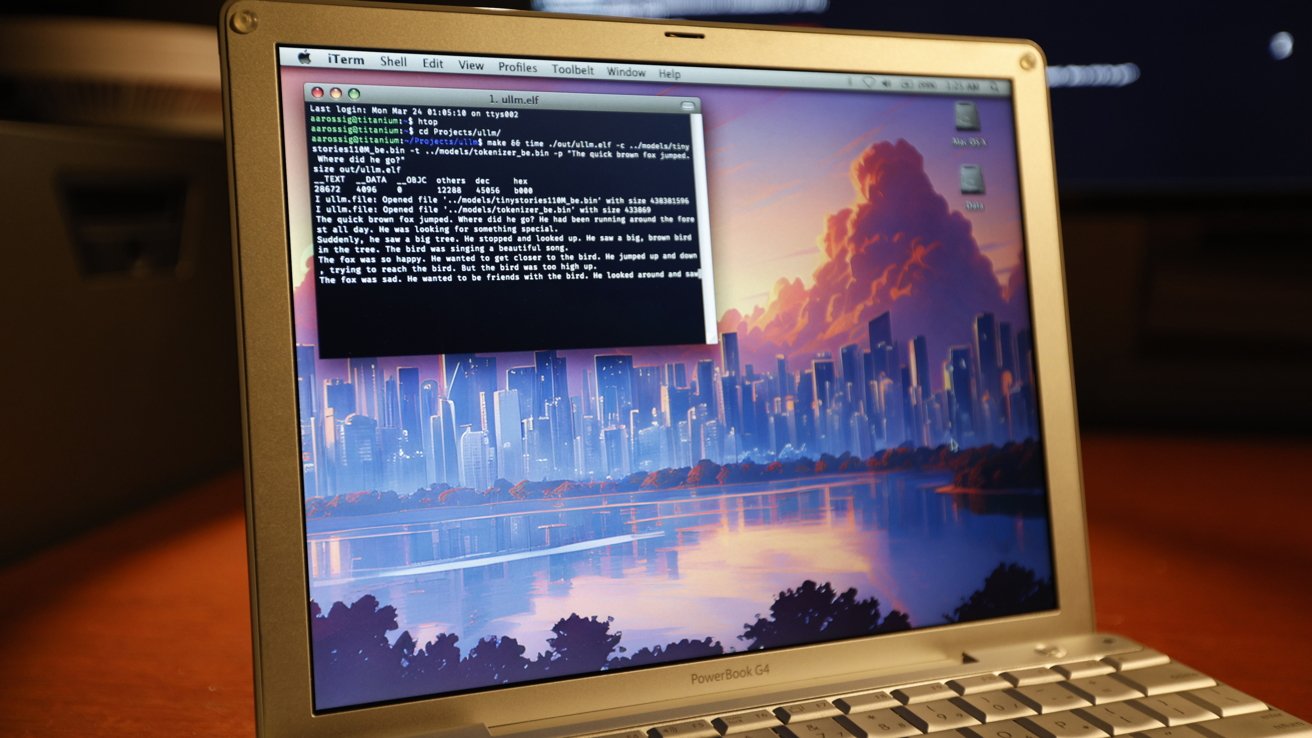
A software developer has proven it is possible to run a modern LLM on old hardware like a 2005 PowerBook G4, albeit nowhere near the speeds expected by consumers.
Most artificial intelligence projects, such as the constant push for Apple Intelligence, leans on having a powerful enough device to handle queries locally. This has meant that newer computers and processors, such as the latest A-series chips in the iPhone 16 generation, tend to be used for AI applications, simply due to having enough performance for it to work.
In a blog post published on Monday by The Resistor Network, Andrew Rossignol — the brother of Joe Rossignol at MacRumors — writes about his work getting a modern large language model (LLM) to run on older hardware. What was available to him was a 2005 PowerBook G4, equipped with a 1.5GHz processor, a gigabyte of memory, and architecture limitations such as a 32-bit address space.
After checking out the llama2.c project to implement the Llama2 LLM inference with a single vanilla C file and no accelerators, Rossignol forked the core of the project to make some improvements.
Those improvements included wrappers for system functions, organizing the code into a library with a public API, and eventually porting the project to run on a PowerPC Mac. This latter point involved issues with the “big-endian” processor, where the model checkpoint and tokenizers instead expect the use of “little-endian” processors, referring to byte ordering systems.
Not exactly fast
The recommendation by the llama2.c project was to use the TinyStories model, which was used to maximize the chance of outputs without specialized hardware acceleration, such as a modern GPU. Testing was mostly done with the 15 million-parameter (15M) variant of the model, before switching to the 110M version, as anything higher would be too large for the address space.
The number of parameters used in a model can result in a more complex model, so the aim is to get as many as possible in use for it to generate an accurate response, without sacrificing the speed of the response. Given the severe constraints of the project, it was a case of choosing models that were small enough to be usable.
To compare the performance of the PowerBook G4 project, it was put against a single Intel Xeon Silver 4216 core clocked at 3.2GHz. The benchmark resulted in a test time for a query of 26.5 seconds and 6.91 tokens per second.
Running the same code on the PowerBook G4 worked, but at a much slower rate of 4 minutes, or nine times slower than the single Xeon core. With more optimizations, including using vector extensions like AltiVec, another half a minute was shaved off the inference operation, or making the PowerBook G4 just eight times slower.
It was found that the selected models were capable of producing “whimsical children’s stories.” This helped lighten the mood during debugging.
Beyond speed
It seems unlikely that there will be much more performance that could be squeezed out of the test hardware, due to limitations like its use of 32-bit and a maximum addressable memory of 4GB. While quantization could help, there’s too little address space to be usable.
Admitting that the project probably stops at this point for the moment, Rossignol offers that the project “has been a great way to get my toes wet with LLMs and how they operate.”
He also adds that “it is fairly impressive that a computer which is 15 years junior [to the Xeon] can do this at all.”
This demonstration of older hardware running a modern LLM gives hope to users that their older hardware could be brought out of retirement and still be used with AI. However, while keeping in mind that the cutting edge software developments will run with limitations and a considerably slower speed than modern hardware.
Short of the discovery of extreme optimizations to minimize the processing requirements, those working on LLMs and AI in general will still have to keep buying more modern hardware for the task.
The latest M3 Ultra Mac Studio is a great, if extremely expensive, way to run massive LLMs locally. But for the hobbyist dabbling in the subject, tinkering with projects like the PowerBook G4 can still be rewarding.


