


During Apple’s “Scary Fast” event, one feature caught my eye unlike anything else: Dynamic Caching. Probably like most people watching the presentation, I had one reaction: “How does memory allocation increase performance?”
Apple based its debut of the new M3 chip around a “cornerstone” feature it calls Dynamic Caching for the GPU. Apple’s simplified explanation doesn’t make it clear exactly what Dynamic Caching does, much less how it improves performance of the GPU on the M3.
I dug deep into typical GPU architectures and sent some direct questions to find out what exactly Dynamic Caching is. Here’s my best understanding of what is undoubtedly the most technically dense feature Apple has ever slapped a brand on.
What exactly is Dynamic Caching?

Dynamic Caching is a feature that allows M3 chips to only use the precise amount of memory that a particular task needs. Here’s how Apple describes it in the official press release: “Dynamic Caching, unlike traditional GPUs, allocates the use of local memory in hardware in real time. With Dynamic Caching, only the exact amount of memory needed is used for each task. This is an industry first, transparent to developers, and the cornerstone of the new GPU architecture. It dramatically increases the average utilization of the GPU, which significantly increases performance for the most demanding pro apps and games.”
In typical Apple fashion, a lot of the technical aspects are intentionally obscured to focus on the outcome. There’s just enough there to get the gist without giving away the secret sauce or confusing audiences with technical jargon. But the general takeaway seems to be that Dynamic Caching allows the GPU to have more efficient memory allocation. Simple enough, right? Well, it’s still not exactly clear how memory allocation “increases the average utilization” or “significantly increases performance.”
To even attempt to understand Dynamic Caching, we have to step back to examine how GPUs work. Unlike CPUs, GPUs excel at handling massive workloads in parallel. These workloads are called shaders, which are the programs that the GPU execute. To effectively utilize a GPU, programs need to execute a ton of shaders at once. You want to use up as many of the available cores as possible.
This leads to an effect that Nvidia calls the “tail.” A load of shaders execute at once, and then there’s a dip in utilization while more shaders are sent to be executed on threads (or more accurately, thread blocks on a GPU). This effect was mirrored in Apple’s presentation when it explained Dynamic Caching, as the GPU utilization spiked before bottoming out.
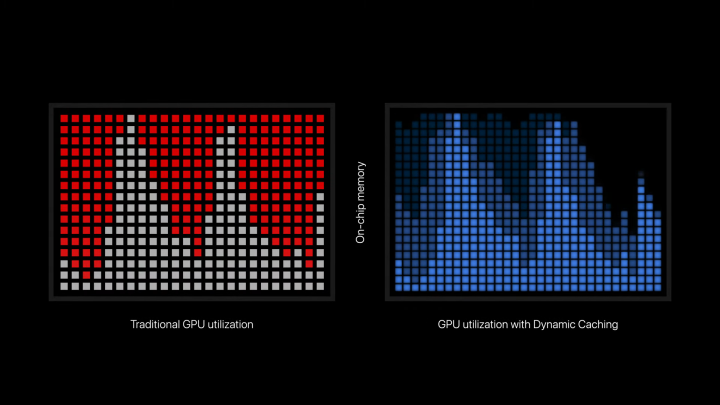
How does this play into memory? Functions on your GPU read instructions from memory and write the output of the function to memory. Many functions will also need to access memory multiple times while being executed. Unlike a CPU where memory latency through RAM and cache is extremely important due to the low level of parallel functions, memory latency on a GPU is easier to hide. These are highly parallel processors, so if some functions are digging around in memory, others can be executing.
That works when all of the shaders are easy to execute, but demanding workloads will have very complex shaders. When these shaders are scheduled to be executed, the memory needed to execute them will be allocated, even if it isn’t needed. The GPU is partitioning a lot of its resources to one complex task, even if those resources will go to waste. It seems Dynamic Caching is Apple’s attempt to more effectively utilize the resources available to the GPU, ensuring that these complex tasks take only what they need.
This should, in theory, increase the average utilization of the GPU by allowing more tasks to execute at once, rather than having a smaller set of demanding tasks gobbling up all of the resources available to the GPU. Apple’s explanation focuses on the memory first, making it seem as if memory allocation alone increases performance. From my understanding, it seems that efficient allocation allows more shaders to execute at once, which would then lead to an increase utilization and performance.
Used vs. allocated
One major aspect that is key to understanding my attempt at an explanation of Dynamic Caching is how shaders branch. The programs your GPU executes aren’t always static. They can change depending on different conditions, which is especially true in large, complex shaders like the ones required for ray tracing. These conditional shaders need to allocate resources for the worst possible scenario, which means some resources could go to waste.
Here’s how Unity explains dynamic branching shaders in its documentation: “For any type of dynamic branching, the GPU must allocate register space for the worst case. If one branch is much more costly than the other, this means that the GPU wastes register space. This can lead to fewer invocations of the shader program in parallel, which reduces performance.”
It appears Apple is targeting this type of branching with Dynamic Caching, allowing the GPU to only use the resources it needs rather than them going to waste. It’s possible the feature could have implications elsewhere, but it’s not clear where and when Dynamic Caching kicks in while a GPU is executing its tasks.
Still a black box

Of course, I need to note that all this is just my understanding, cobbled together from how GPUs traditionally function and what Apple has officially stated. Apple may release more info on how it all works eventually, but ultimately, the technical minutiae of Dynamic Caching doesn’t matter if Apple is, indeed, able to improve GPU utilization and performance.
In the end, Dynamic Caching is a marketable term for a feature that goes deep within the architecture of a GPU. Trying to understand that without being someone who designs GPUs will inevitably lead to misconceptions and reductive explanations. In theory, Apple could have just nixed the branding and let the architecture speak for itself.
If you were looking for a deeper look into what Dynamic Caching could be doing in the M3’s GPU, you now have a possible explanation. What’s important is how the final product performs, though, and we don’t have long to wait until Apple’s first M3 devices are available to the public for us all to find out. But based on the performance claims and demos we’ve seen so far, it certainly looks promising.
Editors’ Recommendations


